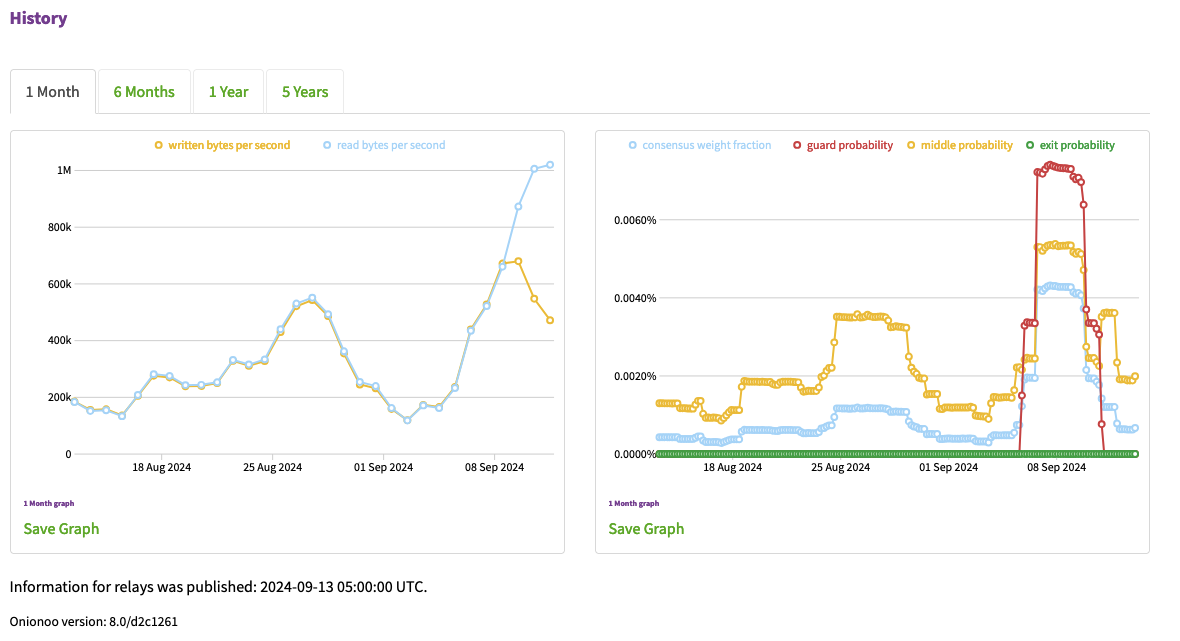
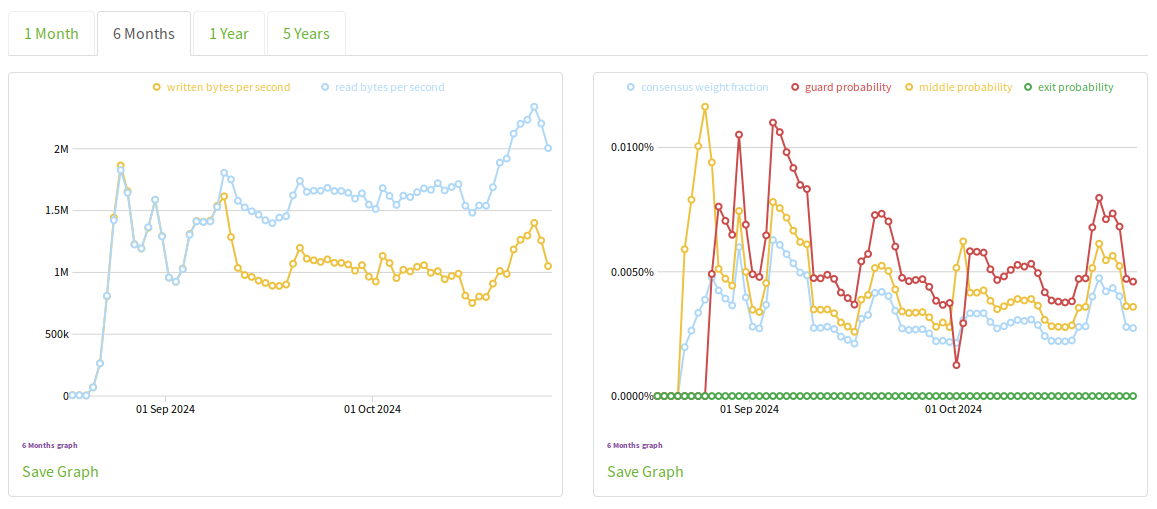
We have 2 relays on 43.228.174.250, on ports 443 and 9001. One of them, menhera1 (2754BC56FEDB3F29008B0DCF583F2F57CB980E81) on port 443 is recently receiving much more traffic than sending, and as this unbalance begin the consensus weight of the relay dropped significantly.
The VM hosting the relays is seemingly not overloaded both CPU-wise and memory-wise… And of course this order of traffic should not fill up the bandwidth capacity.
What’s happening here? Can adding iptables/nftables rules help?
There is an entry for this on the support portal for relay operators. However, I do not think this is the case. The only time this happened to my relays was while the network was affected by multiple DDoS, which got my relays to be overloaded.
Sep 13 06:38:54.000 [notice] No circuits are opened. Relaxed timeout for circuit 236980 (a Measuring circuit timeout 3-hop circuit in state doing handshakes with channel state open) to 60000ms. However, it appears the circuit has timed out anyway. [1 similar message(s) suppressed in last 5580 seconds]
Sep 13 10:28:33.000 [notice] Heartbeat: Tor's uptime is 11 days 17:58 hours, with 2552 circuits open. I've sent 374.71 GB and received 533.28 GB. I've received 1066335 connections on IPv4 and 45581 on IPv6. I've made 254126 connections with IPv4 and 67685 with IPv6.
Sep 13 10:28:33.000 [notice] While bootstrapping, fetched this many bytes: 1792004 (server descriptor fetch); 548620 (consensus network-status fetch); 3742902 (microdescriptor fetch)
Sep 13 10:28:33.000 [notice] While not bootstrapping, fetched this many bytes: 231647325 (server descriptor fetch); 11340 (server descriptor upload); 14052059 (consensus network-status fetch); 87819 (authority cert fetch); 4765767 (microdescriptor fetch)
Sep 13 10:28:33.000 [notice] Circuit handshake stats since last time: 4/4 TAP, 233638/233638 NTor.
Sep 13 10:28:33.000 [notice] Since startup we initiated 0 and received 0 v1 connections; initiated 0 and received 0 v2 connections; initiated 0 and received 30652 v3 connections; initiated 0 and received 210990 v4 connections; initiated 221706 and received 841119 v5 connections.
Sep 13 10:28:33.000 [notice] Heartbeat: DoS mitigation since startup: 10 circuits killed with too many cells, 338341517 circuits rejected, 245 marked addresses, 0 marked addresses for max queue, 0 same address concurrent connections rejected, 0 connections rejected, 0 single hop clients refused, 0 INTRODUCE2 rejected.
Sep 13 10:32:57.000 [notice] No circuits are opened. Relaxed timeout for circuit 240233 (a Measuring circuit timeout 3-hop circuit in state doing handshakes with channel state open) to 60000ms. However, it appears the circuit has timed out anyway.
Sep 13 13:45:11.000 [notice] No circuits are opened. Relaxed timeout for circuit 242869 (a Measuring circuit timeout 3-hop circuit in state doing handshakes with channel state open) to 60000ms. However, it appears the circuit has timed out anyway. [1 similar message(s) suppressed in last 8520 seconds]
Sep 13 14:46:11.000 [notice] No circuits are opened. Relaxed timeout for circuit 243772 (a Measuring circuit timeout 3-hop circuit in state doing handshakes with channel state open) to 60000ms. However, it appears the circuit has timed out anyway. [2 similar message(s) suppressed in last 1440 seconds]
I think that most Tor relays nowadays are running under some firewalls of VPS/cloud providers. Our relays have a direct connection to a BGP backbone, and packets are unfiltered (except bogon filtering and the blocking of outgoing port 25, at the routers), and I suspect that this is making our relays prone to attacks.
It’s a sign of DDoS.
Here are stats from my relay:
Sep 13 19:03:49.000 [notice] Heartbeat: Tor's uptime is 8 days 5:59 hours, with 12491 circuits open. I've sent 603.40 GB and received 592.40 GB. I've received 670658 connections on IPv4 and 3850 on IPv6. I've made 216944 connections with IPv4 and 0 with IPv6.
Sep 13 19:03:49.000 [notice] While not bootstrapping, fetched this many bytes: 166796211 (server descriptor fetch); 4620 (server descriptor upload); 9681151 (consensus network-status fetch); 3067043 (microdescriptor fetch)
Sep 13 19:03:49.000 [notice] Circuit handshake stats since last time: 12/12 TAP, 366333/366333 NTor.
Sep 13 19:03:49.000 [notice] Since startup we initiated 0 and received 0 v1 connections; initiated 0 and received 0 v2 connections; initiated 0 and received 20304 v3 connections; initiated 0 and received 366536 v4 connections; initiated 167388 and received 264040 v5 connections.
Sep 13 19:03:49.000 [notice] Heartbeat: DoS mitigation since startup: 4 circuits killed with too many cells, 112 circuits rejected, 1 marked addresses, 0 marked addresses for max queue, 0 same address concurrent connections rejected, 0 connections rejected, 0 single hop clients refused, 447076 INTRODUCE2 rejected.
Recently the isolated segment of our network hosting two Tor relays, on average, is consuming 8 Mbps download and 4 Mbps upload, which is somewhat unhealthy for relays. I wonder, if bots trying to connect to port 443 assuming HTTPS, is using capacities of the relay menhera1 on port 443.
In these few weeks, I do not see excess incoming traffic in the statistics, on menhera1. The timing for the cease of the possible attack coincides with the downtime for the relay, so I first thought that our relay node was ‘pwned’ or taken down by an attack. But the similar traffic patterns for my friend’s relay also stopped, so it may be that the specific attack or the botnet operation came to an end.
I do not watch precise traffic patterns of the relays closely, for privacy reasons. But our backbone statistics, limited to a coarse timeframe, show that our relays are sometimes communicating heavily via some of our neighboring ASes we are peering with at an IX (I do not state which). Since peering is a local thing, and we are not peering with any of the global large-ish ASes, it is a bit strange thing to be seen, considering Tor usually avoids two adjacent relays in the same country, in a circuit.
@metastable-void: When I first saw this graph, I thought I had stumbled across your server in the stats.
What struck me is that the unbalance seems to have started the exact same day, Sept 9, and looks almost identical in the relative unbalance percentage.
I run multiple relays and use the firewall rules from Enkidu-6 on most of them, but have one server running without them, to see if there are differences. Only the relays without the anti-ddos rules show this behaviour.
It is the usual attack most relays have been going through at one time or another. Read the following and if you find it useful, run the script. It’ll fix the problem:
It might be due to DDoS that my relays are measured slow and not used much despite having an unmetered/unrestricted upstream connection, so I adopted the @Enkidu-6 's script.
Originally the relays had totally unfiltered (except outbound port 25) direct connection to the backbone, and now I applied the script to the host (and I set it up so that it is loaded on startup).
It has been said before, and i remember reading it somewhere here from the Team that’s behind the networking, that the current system of bandwidth measuring (which in turn affects consensus weight a lot), is unfortunately still very location specific, and they’re trying to find a way -or ways- to overcome this.
All that said, an unfiltered/unmitigated relay is going to perform EVEN worse.
Sure, the application itself is going to mitigate it -try at least- , but up to a point.
Not having a good,and practical, “tested and proven” set of anti-DDOS firewall rules, like Enkidu’s , is like adding hurt to hurt.
What’s more, if we think about it, a relay without anti-DDOS fw rules, not only performs worse than it could , but -to some point at least- it propagates and facilitates in its turn, DDOS attacks throughout the Tor Network in general.
So it’s a “double whammy”.
The importance of having good anti-DDOS fw rules in place, can’t be stressed enough, as i see it at least,
and whereas, we, as simple relay contributors to the Network, can’t do something about the former issue, we have ready-made tools at our disposal for the latter.