I’m running Tor with MaxMemInQueues 1 GB for many years.
But today I noticed that Tor process uses 2 GiB of RAM.
What kind of data Tor may store, which is not limited by MaxMemInQueues?
Is it related to latest attacks?
I guess that increase in consumed memory could have happened today at 01:00 UTC, but I’m not sure, I’m not monitoring it directly.
Selection of 75% of total memory is a strange decision.
Tor easily exceeds 1.33 (1 / 0.75) of MaxMemInQueues.
My record is 3.5 GiB working set with MaxMemInQueues 1 GB.
For selecting of the best value for MaxMemInQueues it is better to know at least approximate formula for maximum total memory consumption of Tor process.
With 0.4.7.8 version maximum working set was somewhere near 4.5 GiB.
Then 0.4.7.10 was released and for ~month maximum RAM usage was around 1.6 GiB.
Last week RAM usage started to crawl up and today it is 4.4 GiB again.
Do we need 0.4.7.11 to solve this problem?
1 year passed, no improvements can be seen.
Yesterday DDoS attack on my 0.4.8.9 relay began.
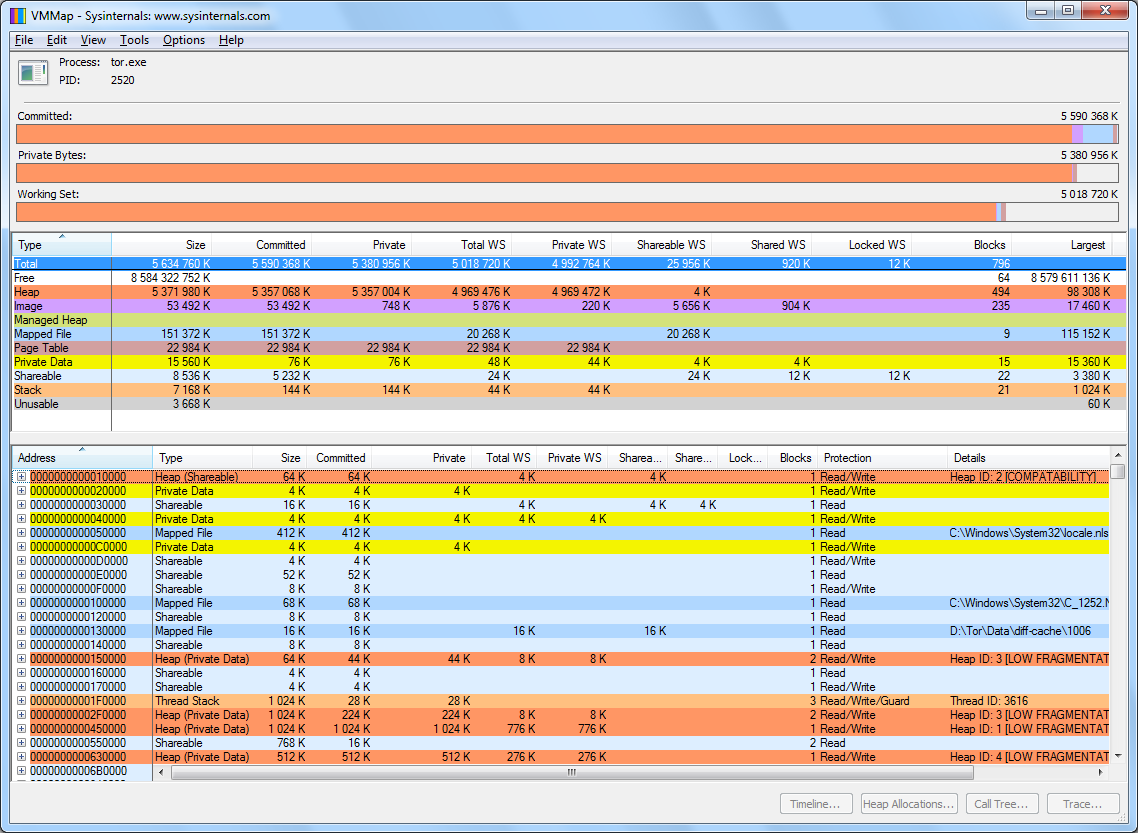
Despite having MaxMemInQueues 512 MB and RelayBandwidthRate 4 MBytes options, tor.exe RAM consumption increased to 5380 MB.
Looks like Tor have memory leaks.
Messages about memory freeing appear in logs, but it does not help to contain RAM consumption growth.
Dec 07 08:10:57.000 [notice] We're low on memory (cell queues total alloc: 373453872 buffer total alloc: 140982272, tor compress total alloc: 0 (zlib: 0, zstd: 0, lzma: 0), rendezvous cache total alloc: 23505346). Killing circuits withover-long queues. (This behavior is controlled by MaxMemInQueues.) Dec 07 08:10:58.000 [notice] Removed 56827584 bytes by killing 4152 circuits; 1530162 circuits remain alive. Also killed 0 non-linked directory connections. Killed 0 edge connections
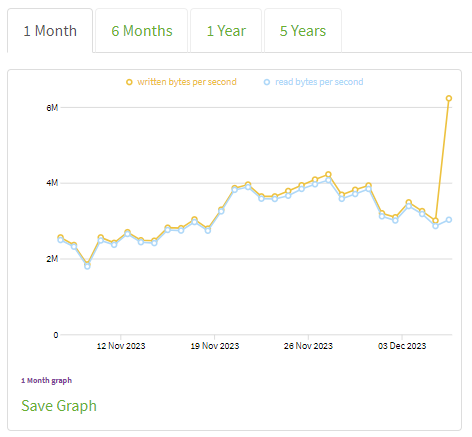
Here is new info regarding overload event for my relay.
After RAM consumption reached 5 GB, I restarted Tor service.
Instantly RAM consumption began to grow again.
When it reached 3 GB, I noticed that alive circuit count start dropping (returning to normal values), indicating that overload went away.
Then I restarted node again to clear mess in RAM and after that consumption stabilized at usual value of 600 MB.
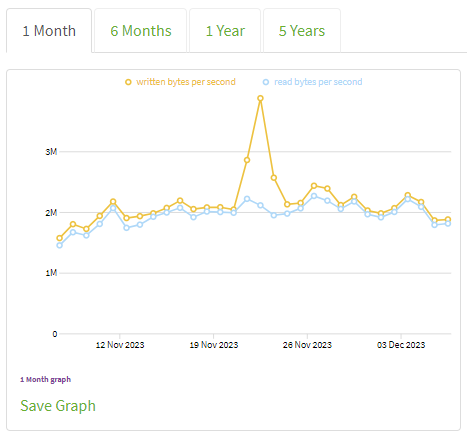
Recently Metrics published fresh charts for traffic consumption and I can see how event reflected there for my relay:
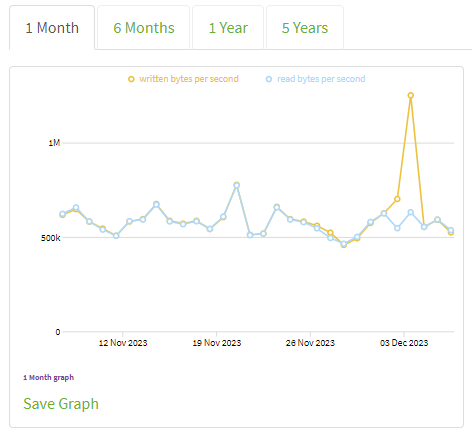
I decided to check if other relays had similar spikes and result was positive:
I do have MaxMemInQueues 96 MB but it does not prevent Tor from being below 1GB of RAM. In my case Tor reports that lzma buffers are huge and attempts to free some memory by killing connections are negligible:
Oct 15 01:13:05.000 [notice] We’re low on memory (cell queues total alloc: 528 buffer total alloc: 0, tor compress total alloc: 683344725 (zlib: 0, zstd: 0, lzma: 683344613), rendezvous cache total alloc: 0). Killing circuits withover-long queues. (This behavior is controlled by MaxMemInQueues.)
Oct 15 01:13:05.000 [notice] Removed 528 bytes by killing 11 circuits; 0 circuits remain alive. Also killed 1 non-linked directory connections. Killed 0 edge connections
—
Oct 18 14:13:06.000 [notice] We’re low on memory (cell queues total alloc: 528 buffer total alloc: 12288, tor compress total alloc: 780965400 (zlib: 0, zstd: 0, lzma: 780965272), rendezvous cache total alloc: 0). Killing circuits withover-long queues. (This behavior is controlled by MaxMemInQueues.)
Oct 18 14:13:06.000 [notice] Removed 8720 bytes by killing 2 circuits; 0 circuits remain alive. Also killed 0 non-linked directory connections. Killed 2 edge connections
Recently I saw this post about compression bomb, so I thought that there are ways to attack/disturb Tor nodes by playing with / pumping decompression requirements. In another post Tor managed to allocate 2147654498 for lzma… insane!
I don’t see currently a way to keep Tor from being OOMKilled unless it learns how to manage compression buffers.
Can you please post the log line that mentions the Tor, ssl and packers versions? Which OS / distro and version is it on? Do you run from source or from a packet system (binary).
Here we go: Tor v0.4.8.18-1~d11.bullseye+1 running on Debian Bullseye 13.1.
Todays’ log:
Nov 11 22:33:06.033 [notice] Tor 0.4.8.18 running on Linux with Libevent 2.1.12-stable, OpenSSL 1.1.1n, Zlib 1.3.1, Liblzma 5.8.1, Libzstd 1.5.7 and Glibc 2.41 as libc.
…
Nov 12 19:01:16.000 [notice] We’re low on memory (cell queues total alloc: 528 buffer total alloc: 184320, tor compress total alloc: 597260954 (zlib: 395520, zstd: 11141352, lzma: 585723954), rendezvous cache total alloc: 0). Killing circuits withover-long queues. (This behavior is controlled by MaxMemInQueues.)
Nov 12 19:01:16.000 [notice] Removed 184848 bytes by killing 1 circuits; 0 circuits remain alive. Also killed 4 non-linked directory connections. Killed 0 edge connections
Tor killed connections and released “just” 180K, while compression buffers are 670M. I can imagine how many connections one can handle with that buffer
# /bin/ps -C tor -o pid,comm,vsz,rss,cmd
PID COMMAND VSZ RSS CMD
2987156 tor 968648 571364 /usr/bin/tor ...
I suspect that due to intensive attempts to free memory, other Tor bugs pop up, see also another my post:
Nov 12 10:27:14.000 [warn] connection_edge_about_to_close(): Bug: (Harmless.) Edge connection (marked at ../src/core/or/circuitlist.c:2716)
hasn't sent end yet? (on Tor 0.4.8.18 )
Nov 12 10:27:14.000 [warn] tor_bug_occurred_(): Bug: ../src/core/or/connection_edge.c:1086: connection_edge_about_to_close: This line should not have been reached. (Future instances of this warning will be silenced.) (on Tor 0.4.8.18 )
Nov 12 10:27:14.000 [warn] Bug: Tor 0.4.8.18: Line unexpectedly reached at connection_edge_about_to_close at ../src/core/or/connection_edge.c:1086. Stack trace: (on Tor 0.4.8.18 )
Nov 12 10:27:14.000 [warn] Bug: /usr/bin/tor(log_backtrace_impl+0x57) [0x560594ec7197] (on Tor 0.4.8.18 )
Nov 12 10:27:14.000 [warn] Bug: /usr/bin/tor(tor_bug_occurred_+0x16b) [0x560594ed22fb] (on Tor 0.4.8.18 )
Nov 12 10:27:14.000 [warn] Bug: /usr/bin/tor(connection_exit_about_to_close+0x1d) [0x560594f7b48d] (on Tor 0.4.8.18 )
Nov 12 10:27:14.000 [warn] Bug: /usr/bin/tor(+0x6f65d) [0x560594e4a65d] (on Tor 0.4.8.18 )
Nov 12 10:27:14.000 [warn] Bug: /usr/bin/tor(+0x6fd6b) [0x560594e4ad6b] (on Tor 0.4.8.18 )
Nov 12 10:27:14.000 [warn] Bug: /lib/x86_64-linux-gnu/libevent-2.1.so.7(+0x21937) [0x7f6b1a1fb937] (on Tor 0.4.8.18 )
Nov 12 10:27:14.000 [warn] Bug: /lib/x86_64-linux-gnu/libevent-2.1.so.7(event_base_loop+0x49f) [0x7f6b1a1fc13f] (on Tor 0.4.8.18 )
Nov 12 10:27:14.000 [warn] Bug: /usr/bin/tor(do_main_loop+0x101) [0x560594e4c761] (on Tor 0.4.8.18 )
Nov 12 10:27:14.000 [warn] Bug: /usr/bin/tor(tor_run_main+0x1e5) [0x560594e48005] (on Tor 0.4.8.18 )
Nov 12 10:27:14.000 [warn] Bug: /usr/bin/tor(tor_main+0x49) [0x560594e44319] (on Tor 0.4.8.18 )
Nov 12 10:27:14.000 [warn] Bug: /usr/bin/tor(main+0x19) [0x560594e43ef9] (on Tor 0.4.8.18 )
Nov 12 10:27:14.000 [warn] Bug: /lib/x86_64-linux-gnu/libc.so.6(+0x29ca8) [0x7f6b19a26ca8] (on Tor 0.4.8.18 )
Nov 12 10:27:14.000 [warn] Bug: /lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x85) [0x7f6b19a26d65] (on Tor 0.4.8.18 )
Nov 12 10:27:14.000 [warn] Bug: /usr/bin/tor(_start+0x2a) [0x560594e43f4a] (on Tor 0.4.8.18 )
Nov 12 10:27:15.000 [notice] We're low on memory (cell queues total alloc: 528 buffer total alloc: 0, tor compress total alloc: 510386111 (zlib: 0, zstd: 22282704, lzma: 488103295), rendezvous cache total alloc: 0). Killing circuits withover-long queues. (This behavior is control:
Thanks for testing tor in relation to memory consumption. I can somehow explain the process needs 1GB of VSS, but honestly saying this is already waaay to much. IMHO, tor relay should work fully functional with 512-1024MB of memory (maybe limiting number of concurrent connections if necessary).
Currently tor process grows its buffers without limit, causing OS to stall (become unresponsive) and then OOMKill. I have “fixed” that by applying memory cap using systemctl:
# systemctl set-property tor MemoryMax=768M
# systemctl status tor@default.service
• tor@default.service - Anonymizing overlay network for TCP
Loaded: loaded (/usr/lib/systemd/system/tor@default.service; enabled-runtime; preset: enabled)
Drop-In: /etc/systemd/system/tor@default.service.d
└─override.conf
Active: active (running) since Fri 2025-11-21 08:19:53 CET; 5 days ago
…
Memory: 642.5M (max: 768M, available: 125.4M, peak: 768M)
CGroup: /system.slice/system-tor.slice/tor@default.service
└─1146001 /usr/bin/tor --defaults-torrc /usr/share/tor/tor-service-defaults-torrc -f /etc/tor/torrc --RunAsDaemon 0
and tor process seems to respect that limit. However it is not happy, as it desperately tries to free memory from circuits, while memory is captured by another part of application (compression buffers):
Nov 26 15:07:19.000 [notice] We're low on memory (cell queues total alloc: 528 buffer total alloc: 0, tor compress total alloc: 683344725 (zlib: 0, zstd: 0, lzma: 683344613), rendezvous cache total alloc: 0). Killing circuits withover-long queues. (This behavior is controlled by MaxMemInQueues.)
Nov 26 15:07:19.000 [notice] Removed 528 bytes by killing 4 circuits; 0 circuits remain alive. Also killed 0 non-linked directory connections. Killed 0 edge connections
Nov 26 16:19:17.000 [notice] We're low on memory (cell queues total alloc: 528 buffer total alloc: 0, tor compress total alloc: 586154674 (zlib: 430592, zstd: 0, lzma: 585723954), rendezvous cache total alloc: 0). Killing circuits withover-long queues. (This behavior is controlled by MaxMemInQueues.)
Nov 26 16:19:17.000 [notice] Removed 528 bytes by killing 2 circuits; 0 circuits remain alive. Also killed 0 non-linked directory connections. Killed 0 edge connections
Nov 26 16:19:18.000 [notice] We're low on memory (cell queues total alloc: 528 buffer total alloc: 0, tor compress total alloc: 488929535 (zlib: 826112, zstd: 0, lzma: 488103295), rendezvous cache total alloc: 0). Killing circuits withover-long queues. (This behavior is controlled by MaxMemInQueues.)
Nov 26 16:19:18.000 [notice] Removed 528 bytes by killing 1 circuits; 0 circuits remain alive. Also killed 0 non-linked directory connections. Killed 0 edge connections
Nov 26 18:00:17.000 [notice] We're low on memory (cell queues total alloc: 528 buffer total alloc: 102400, tor compress total alloc: 488498911 (zlib: 395520, zstd: 0, lzma: 488103295), rendezvous cache total alloc: 0). Killing circuits withover-long queues. (This behavior is controlled by MaxMemInQueues.)