Perhaps we can have this discussion here…
2 Likes
I’ve posted some initial architecure notes ; I’m wondering how well they match (or don’t match) other people’s thinking.
I’ve attempted to summarize the API requirements (not including any architectural requirements) of all of the various potential (listed) arti consumers have based off the original pad. Some of them may be peculiar to how the current tor-daemon integration story works so may not necessarily required based on how the various apps now are forced to interact with tor (particularly around specifically how apps connect to endpoints through tor; SOCKS5 vs ip addresses vs sockets/fds) but I’ve included them anyway.
Once we figure out what a potential API looks like we can more easily figure out what are the RPC requirements.
Summarized/Collated API Requirements
Administration
bootstrapping
network configuration; firewall, proxy, etc
managing onion auth client keys (Tor Browser, Orbot, Gosling)
clearing local Tor data (Orbot)
circuit managaement: close, new (Orbot, Tor Browser)
guard/exit node selection (Orbot
relay allowlist/blocklist (Orbot)
custom/advanced stuffs; bridge+directory authorities (Orbot)
IPV4/IPV6 control (Orbot)
memory controls (Orbot(iOS))
stop all onion services (OnionShare, Gosling)
stop all tor services/daemon (OnionShare)
Debugging/Information
async bootstrap/status events (Gosling, Tor Browser, Orbot)
tor connection status query (Orbot)
log serialization to file on disk (Orbot)
circuit information: IP, geolocation, etc (Tor Browser, Orbot)
all circuits details overview (Orbot)
exit node countries query (Orbot)
getting an onion service’s service id/address (OnionShare)
Pluggable Transports
using tor through PTs
bridge configuration (Tor Browser, Gosling)
standalone PTs for anti-censorship for anti-censorship (Tor Browser)
Connectivity
accessing Tor network via SOCKS5 etc proxies (Tor Browser)
clearnet circuit selection/circuit token (Tor Browser)
communication over Tor via SOCKET/fd/TcpStream (Gosling)
proxy-bypass mode; Tor only for onions, clearnet elsewhere (Orbot)
proxy-bypass mode; use own Tor rather than system (OnionShare)
onion service only mode; only allow connections to onion services (Gosling)
customizable proxy-bypass mode; clarnet connections for some apps; this may make more sense to leave to the embedding app rather than exposed via some API(Orbot)
Onion Services
starting onion service w/ ‘TcpListener’ analog (Gosling)
starting onion service pointing to existing TcpListener (OnionShare)
connecting to onion service w/ ‘TcpStream’ analog (Gosling)
connecting to onion service via Proxy interface (Tor Browser, OnionShare)
connecting to onion service w/ authkey (Tor Browser, Gosling)
onion service domain to local IP Address translation (Orbot)
Cryptography
ed25519 keypair primitive generation, conversion, signing (Gosling)
v3onionservice ↔ ed25519 public key conversions (Gosling)
v3onionservice validation (Gosling, Tor Browser)
x25519 keypair primitive generation, conversion (Gosling)
x25519 ↔ ed25519 keypair conversions (Gosling)
Here is also the brainstorming system architecture I sketched out/mentioned in the mail thread along with that post since we’re migrating discussion to the forum.
(Three-letter acronym appendix at the end just in case)
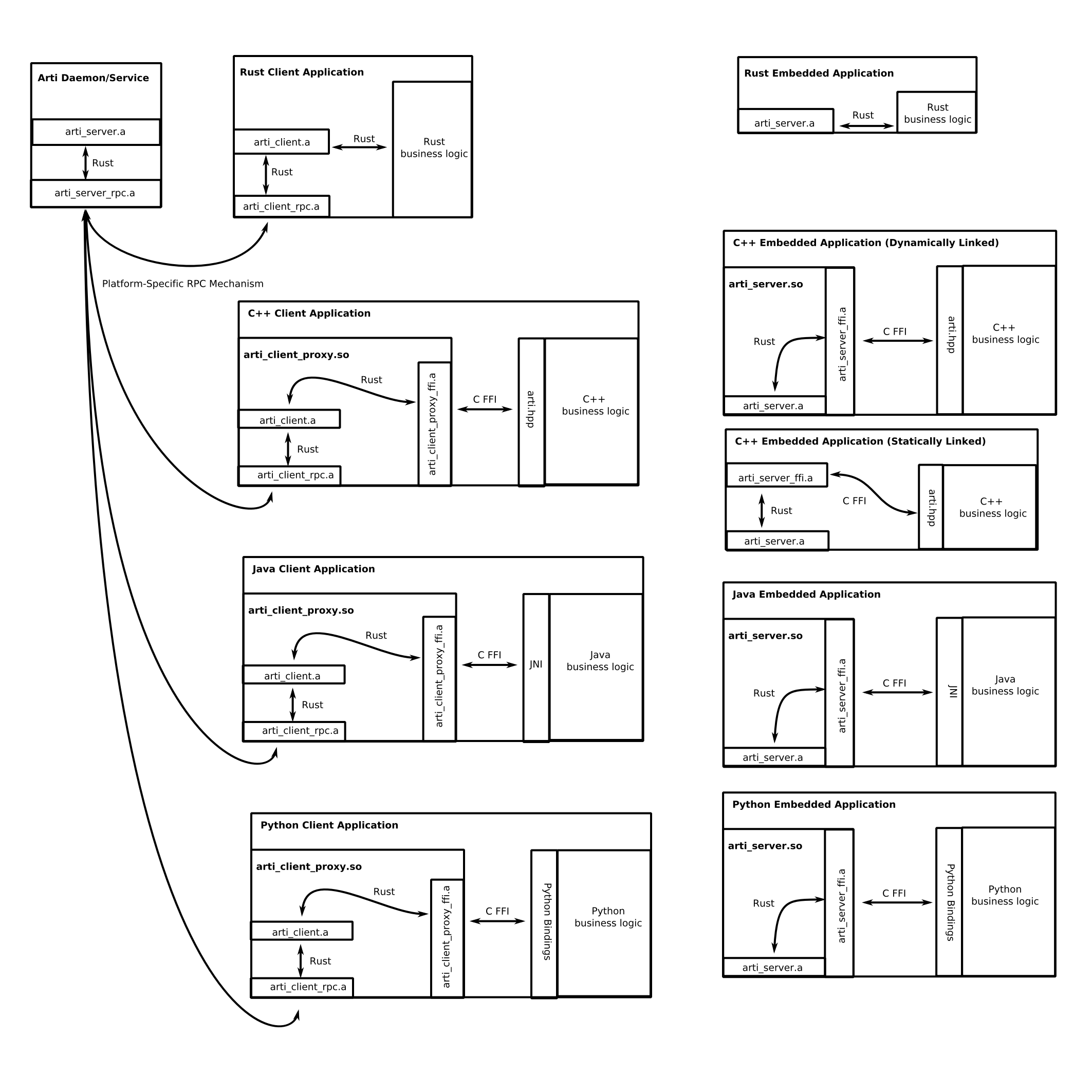
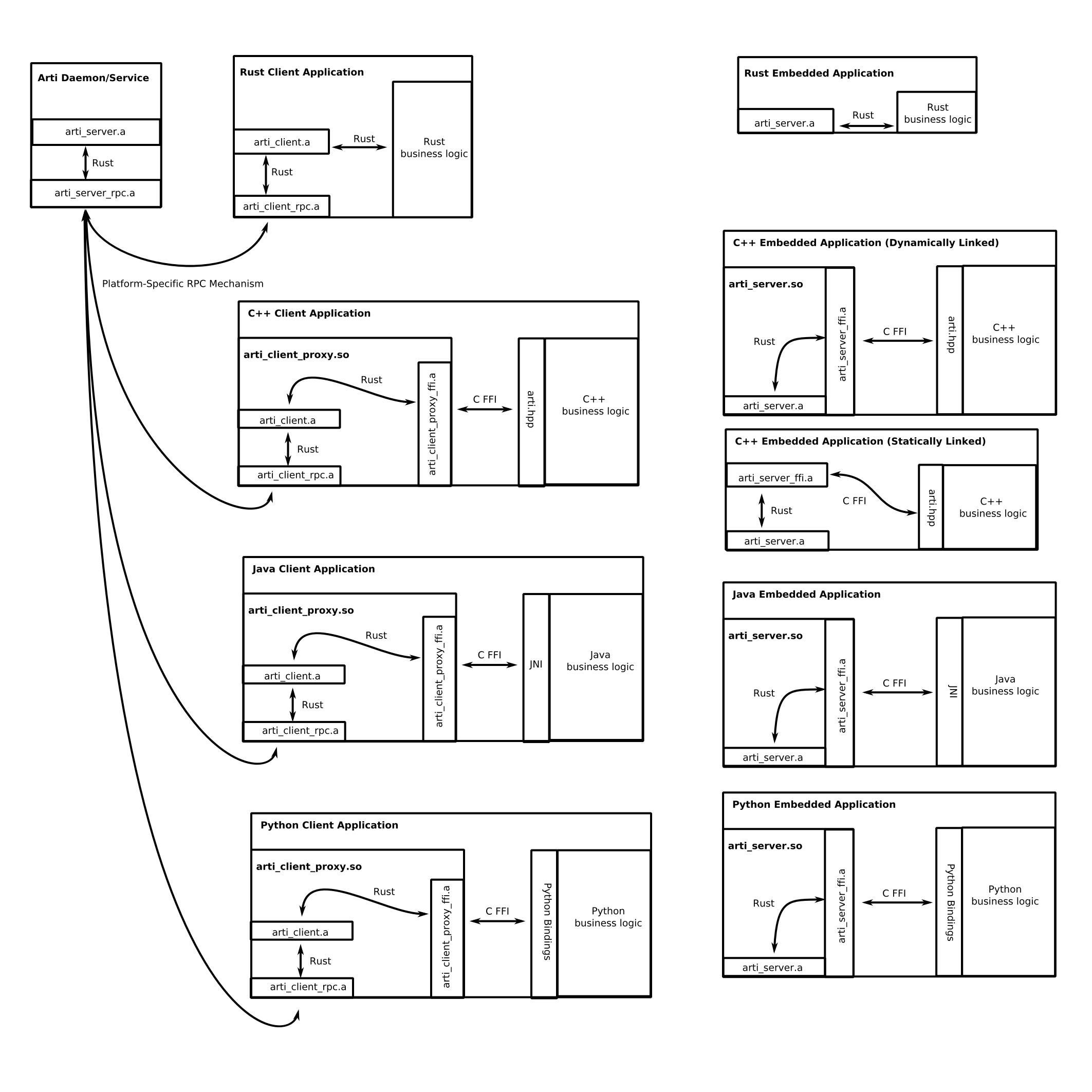
Too big architecture diagram
Drafted up a diagram of how I would go about designing the arti ecosystem components (spoiler alert I don’t have any meaningful experience w/ iOS or Android so this is coming from a desktop-centric point-of-view):
Here’s some definitions of the various components (.a for static libs, .so for dynamically-linked libraries):
- arti_server.a : some public API surface based on the ‘arti’ crate hand waving; this is where the hand-written Rust code goes
- art_server_rpc.a/arti_client_rpc.a : possibly platform specific glue code that handles the actual RPC mechanism
- arti_client.a : client library which exposes the same API as arti_server.a, but transparently routes things through the RPC layer
A project should be able to program against the same ABI and link to either the client or server.
- arti_client_proxy_ffi.a : cbindgen C FFI wrapper around art_client.a
- arti_server_ffi.a : cbindgen C FFI wrapper around arti_server.a
Again these two libs should have exactly the same ABI in the end.
- arti.hpp, JNI, Python Bindings, etc : language specific glue to cbindgen’s generated C header
^these should be generated automatically either from cbdindgen’s generated C header with 3rd party tools if they exist or from using some clang monstrosity if necessary (or even better, from the original IDL source )
Boilerplate, yuck
So, implicit here is a lot of boilerplate to manage/maintain. I would think at a minimum we would want some IDL system in place that lets us define the shared arti_server/arti_client API surface, traits, data types, etc, which then goes and generates the RPC bridge between client/server but also the extern “C” FFI implementation (which is then used to generate the C FFI header using cbindgen). I don’t think this whole pipeline would be unreasonable assuming that the FFI layer is ‘just’ a shim/passthrough layer to the real implementation implemented in arti_server.a.
Some general FFI strats
So one strat here to avoid nasty complications is to only deal in POD C types at the FFI boundary layer (explicitly sized ints except for size_t/usize_t where it makes sense, client-allocated buffers, etc), and to never pass through the actual data out of the Rust layer out into unsafe code (so primitives and handles out only).
Arti’s FFI headers can say functions take pointers to structs but the struct layouts never actually need to be defined anywhere. This way it’s not possible to actually instantiate any of them w/o using arti API calls. So everything public is really uintptr_t handles, but forward declaring as various struct pointers gives us a little type-safety at the boundary layer (to avoid the OpenGL grossness of ‘welp everything is a GLint, good luck with your static analysis’).
This does mean lots of setters and getters everywhere if you need to populate structs member by member (so probably avoid setting up your APIs like that to avoid frequent RPC round-trip to the ‘proxied’ real data on the server).
This setup also helps with ABI stability; you don’t have to worry about accidentally breaking older versions when refactoring your struct layouts if you only ever access them indirectly (and ideally you aren’t changing function signatures between minor releases either).
Further Fanciness
If one wanted to make things easier for downstream apps, it would be nice for the arti_server.so implementation to transparently proxy if a ‘system’ arti server is already in place. This way app developers can ship one binary w/o worrying about whether or not the target system has an arti daemon installed. Alternatively, we can continue with the current approach of ‘set a handful of environment variables to use system tor/arti’, which would still require shipping both the proxying logic and ‘real’ logic in the same arti_server.so library.
SOCKET/file descriptor marshalling?
Another open question which I don’t think was addressed earlier today is how we’re going to handle actual network connections in the proxied scenario (eg arti_client.so ← RPC → arti_server.so ↔ Tor Network). Are we going to be marshalling SOCKETs through the RPC layer (I know this is possible on Windows, no idea about elsewhere)? Will the server just stick with the existing local SOCKS5 proxy paradigm? vOv
Alternatively… Less work?
Instead of maintaining the C FFI layer that exposes arti’s entire public API surface we could just say ‘nope part of using arti in your non-Rust app is writing your own FFI using Rust+cbindgen that exposes only what you need for your business logic’.
I suspect the realities of how Firefox is architected will mean that we will end up having to write our own API boundary thing to deal with exposing arti to XPCOM and JavaScript anyway (may as well do that in Rust), so I don’t think a lack of a C FFI would be a blocker for Tor’s applications team at least but that could change.
Acronyms Just in case
- API - application programming interface (your header definitions)
- ABI - application binary interface (the actual binary blobs your linker/CPU uses, important to remain consistent between releases or consumers have fun runtime errors)
- FFI - foreign function interface ( the sort of general name for the ‘bridge’ between between one type of code like Rust/Java/Python/etc to another, usually C)
- JNI - java native interface (the FFI to get native C ABI stuff callable from your Java code)
- IDL - interface description language (some high-level spec of an API that can be used for boiler plate code generation)
- RPC - remote procedure call (a function call that looks like an ordinary function but actually involves data marshaling and data transmission to another process/machine/etc; looks local but actually out-of-process)
- POD - plane old data (in this context primitive types, int8_t, size_t, float, etc; data which trivially passes through FFI boundaries)
{kind=link}
I think your diagrams basically unify/generalize mine. I’ve no opinion or investment in the specifics of the RPC protocol/message format, and I very much agree that code-generation is very necessary for the whole pipeline to not become a maintenance nightmare.
Going from your diagram, I believe the ideal scenario is some IDL specification of Rust API which generates:
- RPC Server
- RPC Client
- C FFI
as wells as perhaps some portion of Rust API itself (enums, structs, etc) leaving arti devs to only write the Rust API implementation.
I did a little digging last night and was somewhat surprised to find very little available for a general IDL formats+parsers/tooling for code generation (that is actually used/tested). Lots of stuff for converting/generating bridges from one language to another, or some people’s hobby projects, but nothing like OMG IDL to AST.
One approach we could take here is writing Rust API interface in Rust, and then just using the Rust parser to generate the rest.
EDIT: use the Rust parser to generate the AST and from that write code to generate the rest I mean.
Hi! Here are some ideas I’ve had about making FFI/RPC interface for arti. See also
https://gitlab.torproject.org/nickm/arti/-/blob/api-sketch/doc/dev/notes/ffi_and_rpc_sketch.md for some of my earlier thoughts.
I’m summarizing some inline comments that @morgan made on an earlier draft of this. @diziet was also helpful in getting me to walk back some hasty asssumptions.
Each of these ideas stands more or less independently; I’d like it if people would
think about and react to them.
Initial APIs to prototype
What do we build first? We need to pick a minimal set of options that nonetheless are useful, and that demonstrate the whole space of the API that we want to explore.
I suggest:
- Authenticate
- Watch bootstrap status…
* Poll the current status
* Get a stream of status updates - Open a data stream…
* Poll its status
* Get updates about its status
* And use it.
Do we need anything else to be useful?
Will any of our other functionality work differently enough from this functionality
that we need to prototype that too?
(At this point, Richard notes that we maybe want to expose a set of cryptographic operations for key manipulation and management, and wonders whether they should be remote or in-process.)
Idea: Every operation is observable.
Here is a possible principle: Every operation that does not finish in negligible time
should return a handle that you can poll for status information.
For each such handle, you should be able to wait for it to finish, and poll for status
updates.
Idea: Sessions, views, and capabilities
We’d like to have better isolation between different applications than C tor provides on its control ports. Here is one way to achieve that.
We make our API use a capability-like interface, where you can only get a handle to
an object if you have permission to see it and mess with it.
The root object that you get when you authenticate is a View of a TorClient. With a View, you can see the streams and circuits that were opened for that View, but nothing else. One such view is the Global View; it is equivalent to root access on a TorClient instance.
All the Views of a TorClient share a GuardMgr, a CircMgr, a DirMgr, a ChanMgr, and their configuration. You don’t get to expect or modify anything global unless you have the Global View, or we declare that it is safe to inspect.
Each View receives stream isolation from the other Views. (I’ll explain how to associate a stream with a View later on.)
There may be a way to enumerate the streams and circuits associated with a View. Access to a stream, circuit, or View is given by objects that are sort of like capabilities (If you have one, you are presumed to own the object), and sort of like weak handles (The object can go away according to Tor’s regular expiration rules, whether you hang on to the handle or not.)
Idea: Opening streams
If the RPC port is an HTTP(S)-based thing, let’s use some form of HTTP authentication, and also implement an HTTP CONNECT proxy. That way, if
HTTP 2 or later is in use, we get single-socket multiplexing “for free”.
When you’re opening a request via HTTP CONNECT or via SOCKS, let’s define a
way in the request headers to associate your stream with a View. The reply headers
can contain a handle that you can use within the View to refer to the
stream.
(Even if the RPC isn’t HTTPS-based, we can have implement HTTP CONNECT and/or an extended SOCKS with support for more options to achieve this, though we might need to put those on another port.)
Idea: Uniform object manipulation API
Most (not all!) of the actions on Tor’s control port come down to:
- Observe changes in X
- Inspect the current state of X
- Make changes in X
But currently, each of these operations uses a different syntax and namespace, and they are not consistently supported across all objects.
For example, circuits are created or extended with EXTENDCIRCUIT, but you can also act on them with SETCIRCUITPURPOSE and CLOSECIRCUIT. (Those aren’t functions we’re planning to implement in Arti any time soon.) Observing a stream of events where circuits change is SETEVENTS CIRC and/or SETEVENTS CIRC_MINOR. And learning about the set of circuits at a single point in time is GETINFO circ/..
By comparison, configuration is changed with SETCONF and RESETCONF, but also LOADCONF. It’s flushed to disk with SAVECONF. Configuration is observed with SETEVENTS CONF_CHANGED. And to get the current value of a configuration option, you use GETCONF.
I suggest that we try to make a more orthogonal API, where objects of each type are discoverable in the same way, observable in the same way, modifiable in the same way. This will ideally turn an M*N API design (operations * objects) into an M+N design (operations + objects).
Hi arti people!
At Tails, we looked at this forum topic in order to understand whether/how much this will be enough for our specific needs.
The short summary is: the plan seems very good, will probably account for 99% of our needs. Thanks for that!
Still, there are some things we’d like to check so that we can plan our work better.
Can we get rid of onion-grater?
Right now, Tails has something called onion-grater. It is a proxy which acts as an application-level firewall; tis goal is allowing specific applications to run specific commands on the Tor Control Port.
It seems arti will make onion-grater (and control filtering in general) mostly obsolete:
- an application that uses the control mechanism will only get a limited “view” of internals (circuits, streams) that are associated to that application
- there are unprivileged control sessions that seem like they mostly have access to the stream/circuit state of the associated application; a privileged session is needed to actually configure arti (e.g. set a bridge)
These are the main issues that onion-grater tries to solve, so yay. However, there are still some things that are unclear:
- will unprivileged sessions still have access to some sensitive global state/configuration? E.g.
getinfo addresswhich leaks “the best guess at our external IP address”. - what about onioncircuits? It would ideally use an unprivileged control session so it cannot change the configuration, but it would need access to all circuit/stream state, which seems like something unprivileged sessions won’t have by design. Could there be something like a privileged session that is read-only?
Knowing this kind of details is important for us, because it impacts whether we’ll need to reimplement onion-grater for the new protocol, or just drop it altogether.
Tor Connection Assistant
Tails has its own way of configuring access to Tor (this includes, but not limited to, letting the user choose whether they want to use bridges or not).
That’s the main thing we want to migrate.
Restarting tor
Right now, we restart tor when connectivity changes. This is for two reasons:
- Sometimes tor doesn’t connect automatically after changing the network. Restarting it is a workaround for that.
- tor doesn’t reset it’s bootstrap status when the network is changed, which we use to display the progress to the user.
But when we restart tor, we lose all the options we set via ControlPort (ie:Bridge). So we useSAVECONFbefore restart to persist those options.
So, we either need to remove the need for restarting, or a way to save the configuration.
Other needs
Here you can find the authoritative list of how Tor Connection Assistant uses the Control Port:
- We need
status/bootstrap-phaseandstatus/circuit-establishedto display a progress bar / know which bootstrap phase tor is in. That’s probably already accounted for. - Currently we need to disable the sandbox (and restart tor) when the user chooses to use obfs4. This is because we want to enable Sandbox, but you can’t use Sandbox when you use obfs4. This might be very
tor-specific, but still, we need some way to configure obfs4 bridges. - Network Configuration:
- Bridge
- Socks4Proxy
- Socks5Proxy
- HttpsProxy
- Socks5ProxyUsername
- Socks5ProxyPassword
- HttpsProxyAuthenticator
- Currently we start tor with
DisableNetwork 1to configure things via the control port before settingDisableNetwork 0to make it connect. From arti we need some way to configure it before it makes connections. We understand this is the normal way of operating arti, but still, please keep this in mind
- We need to be able to configure the above network settings globally, for all sessions (i.e. if a user configures a bridge in our Tor Connection assistant, it should be used by all applications which use Tor).
Once there is an early version of arti available which includes this API, we would like to test it and could then tell you what’s missing for our needs.
Our +1 on the Summarized/Collated API Requirements
The previous chapter boils down to us adding our +1 to this:
- network configuration; firewall, proxy, etc
- using tor through PTs
- bridge configuration
- standalone PTs for anti-censorship
Onioncircuits
OnionCircuits is a Tails application that let you see Tor circuits.
Current onioncircuits needs are explained in onioncircuits.yml. Specifically:
circuit-statusstream-status- STREAM events
- CIRC events
We understand that this might be part of all circuits details overview (currently required by Orbot only, so +1 for that!) and circuit information: IP, geolocation, etc
It would be good if we could have it, but Onioncircuits is not critical for Tails.
Hi, @boyska! This is helpful, thank you!
(Whoops, I hit “save” too soon. I’ve edited the post to be more full.)
Things are still a work-in-progress, so we can’t be too definite about what will appear eventually vs what will appear in the first release of RPC functionality, but here are some thoughts:
Can we get rid of onion-grater?
We hope so, yes, for most applications. We’re going towards a capabilities-based model, where each session only gets the capabilities it needs.
That said, capabilities design will need some work to be done well. It is entirely possible that the first version of some of the capabilties we design will expose too much or too little. It’s also possible that you’ll want to sandbox applications in ways that are not supposed by a naive version of our capability configuration system.
In these cases, if your application is mostly trusted, and we do our job right, you could configure it to make a privileged connection, and then drop the capabilities that it doesn’t need. If your application is mostly untrusted, you’d have to either configure a “semi-trusted” access level for it (which is still unspecified), or you’d need a mini-oniongrater that makes a connection, drops the capabilities it doesn’t need, and passes the connection along.
For your examples:
will unprivileged sessions still have access to some sensitive global state/configuration? E.g.
getinfo addresswhich leaks “the best guess at our external IP address”.
Easy answer: I hope that we avoid exposing stuff like “what is our external address” to most applications.
Hard answer: sadly there are LOTS of ways that a hostile application can expose this information if it wants to. Like, if we allow applications to choose circuit paths, it can expose the IP address by building a circuit to a cooperating unlisted relay. If the application has access to the OS, it can ask the OS and then relay that information over Tor.
Even if a hostile application is able to do nothing besides open streams over Tor, it can use that ability to open a bunch of high-volume streams and use create traffic patterns on them to interfere with the user’s other traffic. If these traffic patterns are visible remotely, it could use them to render the user’s other circuits linkable to one another and to the attacker’s stream.
That is to say: The design of any Tor-client RPC restriction system is mainly able to restrict what honest applications can do by accident. If your threat model includes hostile applications trying to exploit resource-based side channels, we can’t help you here.
- what about onioncircuits? It would ideally use an unprivileged control session so it cannot change the configuration, but it would need access to all circuit/stream state, which seems like something unprivileged sessions won’t have by design. Could there be something like a privileged session that is read-only?
This would have to be defined in the capabilities-based system; there’s nothing in principle stopping there from being a read-only version of the “access circuit list” capability. (Though we haven’t roadmapped building the “access circuit list” capability at all in v0.)
So: This is possible in principle in the design, though it won’t be in v0. ![]()
Tor Connection Assistant
This should be possible in principle.
Restarting
tor
The issues here (No automatic reconnection, no reset of bootstrap status) sound like bugs or misfeatures that we’ll need to resolve in arti, or make sure that we don’t add in the first place.
Other needs
This is very helpful, thank you !
Not all of this functionality is currently implemented in Arti, and it’s going to have some work to do before we could build it. (It won’t be in the v0 implementation of our RPC system, which is going to be focused on low-privilege use-cases.)
Once there is an early version of
artiavailable which includes this API, we would like to test it and could then tell you what’s missing for our needs.
Is it possible that you could try out an earlier version of the RPC API for experimental purposes at least?
The issue here is that there is a lot of functionality to build before all of the features you have listed here will work. (We don’t have disable-network, we don’t have non-bridge proxies, etc.) But if we wait until those are implemented before you try the RPC system at all, we’ll likely find out any issues that you have in our current designs too later for them to be easily changed.
Can we get rid of onion-grater?We hope so, yes, for most applications
thanks for the detailed answer. I never realized how hard it is to make such an RPC robust against hostile applications!
Once there is an early version of arti available which includes this API, we would like to test it and could then tell you what’s missing for our needs.
Is it possible that you could try out an earlier version of the RPC API for experimental purposes at least?
Yes, we could do that! Can you tell us when it will be a good time to test arti’s RPC?
Yes, we could do that! Can you tell us when it will be a good time to test arti’s RPC?
I wish I knew! I would love to promise a solid date, but I worry that any estimate I make will be inaccurate. I’ll make sure to post on this forum as we’re getting closer to it, though.
Hi arti people, I hope you had a great winter break ![]()
Do you have any news about RPC in Arti? We’d love to have a first iteration of development around arti. When do you think we’ll have an opportunity to test something?
We had a look at your plans on Arti: RPC Support · Milestones · The Tor Project / Core / Arti · GitLab . Do you already have plans about what you will implement first and what probably will be postponed? As an example, knowing if/when you will implement the ability to drop capabilities would allow us to estimate work appropriately.
And since we’re at it: if you think we could be help you with planning or anything, don’t hesitate to ping us!
This isn’t the formal RPC/FFI interface, but we have made progressing building interfaces for Swift/iOS and JNI/Android interfaces for use of Arti on mobile.
You can see the work here: guardianproject / Arti Mobile Experimental · GitLab
Specifically, you can see the calls we make to start Tor and configure a plubbale transport: common/src/lib.rs · main · guardianproject / Arti Mobile Experimental · GitLab
This is expose as a single “start_arti_proxy” function in our library, that is then invoked through the native interface interaction on the mobile platforms.
We’ve also implemented some simple logging callbacks.
Hi, @anonym! Thanks for checking in!
We’ve been pretty busy for the last while trying to get onion services to work. Hopefully, we’ll wrap that part up soon. After that, we’ll likely get to work on roadmapping our next steps: it’s not yet clear whether we’ll be working only on onion service security features, or whether we’ll also parallelize work on RPC and/or initial relay features.
When we do work on RPC, I bet that the initial features will be quite minimal: I would guess that the first things to work on would be managing streams, looking at circuit paths, and possibly adjusting the configuration. After we have the basic pieces in, however, we’ll probably base our next steps on the results of testing and experimentation from people who want to use arti.
Unfortunately I don’t have solid estimates on any of this yet, other than “some time this year, hopefully starting in the first half of the year”. I’ll try to post more details here once we know them.
And since we’re at it: if you think we could be help you with planning or anything, don’t hesitate to ping us!
Thanks! Right now the most useful thing anything can do with Arti is to try to use it, and start to learn your way around the codebase, and report bugs that you find.