Part 3 - Looking for feedback on our Tor relay configuration decision:
Looking for guidance on optimizing server / bandwidth spending for Tor guard / middle relays across datacenters.
Our current setup:
- All same cost: Three servers in different datacenters, each with 10 Gbps unmetered bandwidth.
- Identical hardware/software: Each server has 128 threads, 512GB–768GB RAM, and the same software stack.
- Diversity benefits: Each server hosts fewer than 10 other relays, enhancing overall network diversity.
- Primary differences: Geographic location and upstream peering/routing.
Current Utilization:
- Server 1: 2Gbps utilized (20% utilization)
- Server 2: 6Gbps utilized (60% utilization)
- Server 3: 8Gbps utilized (80% utilization)
Overall, using 16 Gbps out of 30 Gbps purchased – roughly half our bandwidth is idle / “wasted”.
Assuming we can’t significantly optimize these servers any further and given the significant under utilization on Server 1 (80% idle) and Server 2 (40% idle), what would you do in this scenario? Some options we’re considering:
- Consolidation: Paying only for the servers with the highest utilization.
- Repurposing: Allocating the idle bandwidth to another purpose that benefits Tor (or a similar effort).
- Reinvestment: Using the funds from Servers 1 and 2 to acquire additional high-utilization capacity (e.g., more of Server 3 configuration) to boost our overall contribution closer to 24 Gbps.
- Other strategies: Any alternative approaches you might suggest.
Appreciate any thoughts or best practices to help reduce wasted expenditure while maximizing the utility of our available resources.
Thanks for your insights!
Hello,
First of all, thank you for your contribution in helping the Tor Network grow.
I took a look at your family of relays. I think the main issue is that your relays are still fairly new on the Tor network so the usage isn’t that high. It often takes months to see the growth in utilization and traffic.
I often found that in order to get higher utilization and traffic, it would require your servers to be located in EU or at least US East so you have good peering and routing to the rest of the relay servers.
Personally, I run most of my relays using VPSes rather than large dedicated servers because it gives me a lot of flexibility to cancel when things don’t work out or scale easily when needed.
Regarding what you should do? I think you should downsize the hardware on your dedicated servers and look for providers in US East and EU that can offer both large amount of bandwidth preferably unmetered but also have excellent peering/connection to high Tor traffic providers like Hetzner, OVH. In terms of hardware, Unless, you are expecting enormous traffic, there is simply no need to have such a high spec dedicated server. I’m sure it is not cheap to run them. Hope this helps!
John
···
On Fri, Apr 4, 2025, at 2:00 AM, Tor at 1AEO via tor-relays wrote:
Part 3 - Looking for feedback on our Tor relay configuration decision:
Looking for guidance on optimizing server / bandwidth spending for Tor guard / middle relays across datacenters.
Our current setup:
-
All same cost: Three servers in different datacenters, each with 10 Gbps unmetered bandwidth.
-
Identical hardware/software: Each server has 128 threads, 512GB–768GB RAM, and the same software stack.
-
Diversity benefits: Each server hosts fewer than 10 other relays, enhancing overall network diversity.
-
Primary differences: Geographic location and upstream peering/routing.
Current Utilization:
-
Server 1: 2Gbps utilized (20% utilization)
-
Server 2: 6Gbps utilized (60% utilization)
-
Server 3: 8Gbps utilized (80% utilization)
Overall, using 16 Gbps out of 30 Gbps purchased – roughly half our bandwidth is idle / “wasted”.
Assuming we can’t significantly optimize these servers any further and given the significant under utilization on Server 1 (80% idle) and Server 2 (40% idle), what would you do in this scenario? Some options we’re considering:
-
Consolidation: Paying only for the servers with the highest utilization.
-
Repurposing: Allocating the idle bandwidth to another purpose that benefits Tor (or a similar effort).
-
Reinvestment: Using the funds from Servers 1 and 2 to acquire additional high-utilization capacity (e.g., more of Server 3 configuration) to boost our overall contribution closer to 24 Gbps.
-
Other strategies: Any alternative approaches you might suggest.
Appreciate any thoughts or best practices to help reduce wasted expenditure while maximizing the utility of our available resources.
Thanks for your insights!
tor-relays mailing list – tor-relays@lists.torproject.org
To unsubscribe send an email to tor-relays-leave@lists.torproject.org
2Gbps means 1Gbps in and 1Gbps out.
Thanks
···
On Friday, April 4th, 2025 at 1:00 PM, Felix via tor-relays <tor-relays@lists.torproject.org> wrote:
Hey
thanks for sharing your results and questions.
> Part 3 - Looking for feedback on our Tor relay configuration decision:
Sorry for asking, if you don't mind sharing your family name or
fingerprints? Would be awesome.
> Current Utilization:
> - Server 1: 2Gbps utilized (20% utilization)
Does 2Gbps in that context mean 2Gbps inbound plus 2Gbps outbound or
1Gbps in and 1Gbps out?
Cheers, Felix
_______________________________________________
tor-relays mailing list -- tor-relays@lists.torproject.org
To unsubscribe send an email to tor-relays-leave@lists.torproject.org
_______________________________________________
tor-relays mailing list -- tor-relays@lists.torproject.org
To unsubscribe send an email to tor-relays-leave@lists.torproject.org
I’m looking for strategies to boost bandwidth utilization outside the concentrated EU to prevent underutilization and potential financial loss.
Despite the relays being ~30 days old, they already exhibit the same geographic pattern you mention! US East relays get more traffic—and sooner. EU relays dominate the top 30 by advertised bandwidth and consensus weight (see Tor Metrics).
Given this, how can relays outside US East and EU improve their bandwidth utilization?
Is there a critical mass—say, a few thousand relays in a new region or continent—that would shift this balance?
Could this bias be due to the concentration of relays in EU and US East (e.g., through providers like Hetzner and OVH), or might the geographic and routing characteristics of the bandwidth authorities also play a role?
Yes, acknowledging that the current dedicated servers might continue to be underutilized by Tor relays and then I’ll downsize them. The CPU thread counts, 88+, were based on previous guidance on this list for high end deployments, >=10 Gbps. Will see when relays are older how this sorts out.
···
On Friday, April 4th, 2025 at 6:14 PM, John Crow admin@prsv.ch wrote:
Hello,
First of all, thank you for your contribution in helping the Tor Network grow.
I took a look at your family of relays. I think the main issue is that your relays are still fairly new on the Tor network so the usage isn’t that high. It often takes months to see the growth in utilization and traffic.
I often found that in order to get higher utilization and traffic, it would require your servers to be located in EU or at least US East so you have good peering and routing to the rest of the relay servers.
Personally, I run most of my relays using VPSes rather than large dedicated servers because it gives me a lot of flexibility to cancel when things don’t work out or scale easily when needed.
Regarding what you should do? I think you should downsize the hardware on your dedicated servers and look for providers in US East and EU that can offer both large amount of bandwidth preferably unmetered but also have excellent peering/connection to high Tor traffic providers like Hetzner, OVH. In terms of hardware, Unless, you are expecting enormous traffic, there is simply no need to have such a high spec dedicated server. I’m sure it is not cheap to run them. Hope this helps!
John
On Fri, Apr 4, 2025, at 2:00 AM, Tor at 1AEO via tor-relays wrote:
Part 3 - Looking for feedback on our Tor relay configuration decision:
Looking for guidance on optimizing server / bandwidth spending for Tor guard / middle relays across datacenters.
Our current setup:
-
All same cost: Three servers in different datacenters, each with 10 Gbps unmetered bandwidth.
-
Identical hardware/software: Each server has 128 threads, 512GB–768GB RAM, and the same software stack.
-
Diversity benefits: Each server hosts fewer than 10 other relays, enhancing overall network diversity.
-
Primary differences: Geographic location and upstream peering/routing.
Current Utilization:
-
Server 1: 2Gbps utilized (20% utilization)
-
Server 2: 6Gbps utilized (60% utilization)
-
Server 3: 8Gbps utilized (80% utilization)
Overall, using 16 Gbps out of 30 Gbps purchased – roughly half our bandwidth is idle / “wasted”.
Assuming we can’t significantly optimize these servers any further and given the significant under utilization on Server 1 (80% idle) and Server 2 (40% idle), what would you do in this scenario? Some options we’re considering:
-
Consolidation: Paying only for the servers with the highest utilization.
-
Repurposing: Allocating the idle bandwidth to another purpose that benefits Tor (or a similar effort).
-
Reinvestment: Using the funds from Servers 1 and 2 to acquire additional high-utilization capacity (e.g., more of Server 3 configuration) to boost our overall contribution closer to 24 Gbps.
-
Other strategies: Any alternative approaches you might suggest.
Appreciate any thoughts or best practices to help reduce wasted expenditure while maximizing the utility of our available resources.
Thanks for your insights!
tor-relays mailing list – tor-relays@lists.torproject.org
To unsubscribe send an email to tor-relays-leave@lists.torproject.org
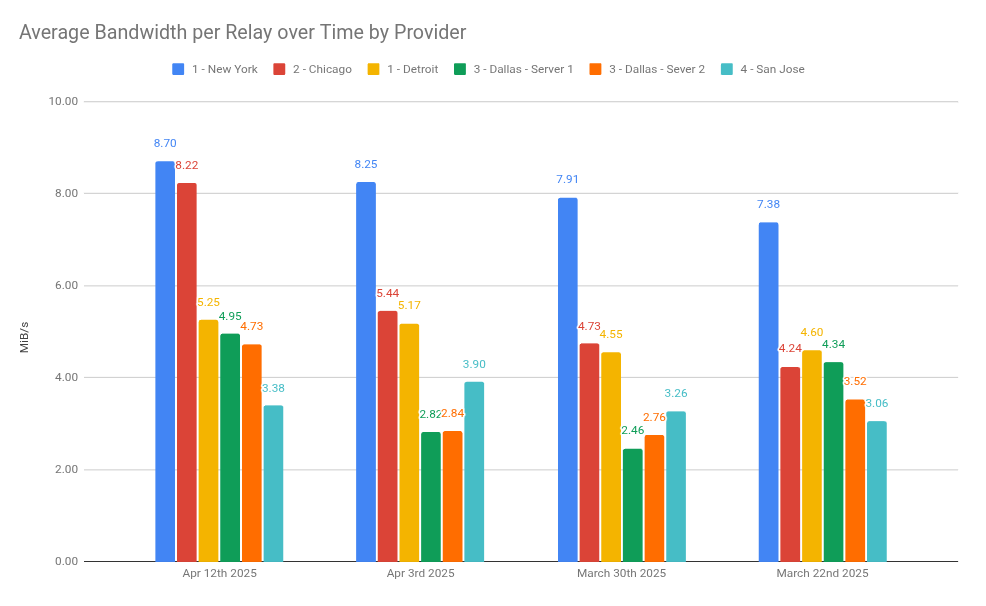
Summary:
New York and Chicago locations had the highest average bandwidth per relay.
San Jose had the consistently lowest average bandwidth per relay.
Dallas and Detroit are slowly increasing, but hard to see the same potential of New York and Chicago.
Main constraint preventing broader evaluation is the ~360 relays per family: zimmer family hitting max descriptor size (#40837) · Issues · The Tor Project / Core / Tor · GitLab
Next steps:
Discontinuing Detroit and Dallas - Sever 2.
Starting servers with a 5th provider in New Jersey and Montreal.
Tempted to add an extra server in New York and Chicago, but will see how 5th provider goes first.
Details:
New York increased the fastest and has stayed at number one.
Chicago had steady increases but recently had significant increase.
Detroit has slow and steady increase. If Chicago wasn't doing so much better, would have Detroit operate longer.
Dallas seems a very slow increase. The dips were due to two moves from rented IPv4 to owned IPv4. Will give it another month or so and see where it ends up.
Disappointed in San Jose consistently at the bottom.
Overview of data and servers:
Covering first ~2 months of ~340 guard relays across 4 different providers in 5 different US-based geographic locations.
All relays with roughly the same average life of ~2 months by the April date.
The servers are all 88 threads to 128 threads with 384GB to 768GB RAM and each on 10 Gbps dedicated unmetered connections.
The servers are all running Ubuntu 24.04.02 with latest Tor relay versions.
Half the servers using owned IPv4 with my ASN and half using rented IPv4 with provider ASN.
Each server is roughly $500/mo and majority are privately negotiated because list prices are 2-5x higher.
Every provider said they're comfortable with Tor traffic but most weren't familiar with the details.
Source: All data from metrics.torproject.org
Table and chart attached as screenshots and text table pasted below.
Table in text:
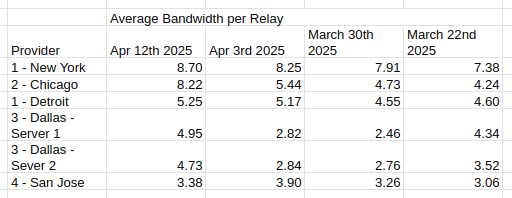
Average Bandwidth per Relay
Provider Apr 12th 2025 Apr 3rd 2025 March 30th 2025 March 22nd 2025
1 - New York 8.70 8.25 7.91 7.38
2 - Chicago 8.22 5.44 4.73 4.24
1 - Detroit 5.25 5.17 4.55 4.60
3 - Dallas - Server 1 4.95 2.82 2.46 4.34
3 - Dallas - Sever 2 4.73 2.84 2.76 3.52
4 - San Jose 3.38 3.90 3.26 3.06
For Felix, most relays have HsDir flag and average uptime for a week or two or three, depending on when last Tor version bumped.
Likely when you review relays had just been upgraded so HsDir flag often drops for a few days.
···
On Saturday, April 5th, 2025 at 1:03 PM, Felix via tor-relays <tor-relays@lists.torproject.org> wrote:
Hi
> > Part 3 - Looking for feedback on our Tor relay configuration
> > decision:
> >
> > Looking for guidance on optimizing server / bandwidth spending for
> > Tor guard / middle relays across datacenters.
> Relay Search
> 2Gbps means 1Gbps in and 1Gbps out.
Thanks for the informations.
> > Overall, using 16 Gbps out of 30 Gbps purchased --
> > roughly half our bandwidth is idle / "wasted"
Is it right that most (all?) relays are not older than mid of March?
If so please take a look at
The lifecycle of a new relay | The Tor Project .
As for as I see the relay status page shows not a single relay with a
HsDir flag and no uptime above 2 days.
Gaining a trustful relay with good traffic needs much more time alive
of the relays (keys). Easily 3 to 6 months.
The relays are on up to date Tor versions 4.8.15 and 4.8.16 what is
good!
My recommendation is to let them brew for 2 months. The situation will
change.
Cheers and happy relaying, Felix
_______________________________________________
tor-relays mailing list -- tor-relays@lists.torproject.org
To unsubscribe send an email to tor-relays-leave@lists.torproject.org
(attachments)
Hello,
New York and Chicago are both major hubs so it makes sense why they have highest average bandwidth. Keep in mind, When providers say New York most of the time it is just Secaucus, NJ. There are multiple datacenter right next to each other.
I would recommend looking at some other locations you should look at is Ashburn, VA and Miami, FL. Ashburn is already a well established hub in the US due to the growing number of cloud datacenter located there. It has excellent connectivity to both the rest of US and EU. In addition, it also helps alleviate the congestion between NY/NJ and EU. Miami has lately been one of the up and coming locations because it is connected to US, South America and EU via NY. Both of these locations seem to do well for Tor.
With San Jose, it makes sense why it is underperforming. Often times traffic has an extra hop because it all has to go through Los Angeles.
···
On Wed, Apr 16, 2025, at 12:03 AM, Tor at 1AEO via tor-relays wrote:
Summary:
New York and Chicago locations had the highest average bandwidth per relay.
San Jose had the consistently lowest average bandwidth per relay.
Dallas and Detroit are slowly increasing, but hard to see the same potential of New York and Chicago.
Main constraint preventing broader evaluation is the ~360 relays per family: https://gitlab.torproject.org/tpo/core/tor/-/issues/40837
Next steps:
Discontinuing Detroit and Dallas - Sever 2.
Starting servers with a 5th provider in New Jersey and Montreal.
Tempted to add an extra server in New York and Chicago, but will see how 5th provider goes first.
Details:
New York increased the fastest and has stayed at number one.
Chicago had steady increases but recently had significant increase.
Detroit has slow and steady increase. If Chicago wasn’t doing so much better, would have Detroit operate longer.
Dallas seems a very slow increase. The dips were due to two moves from rented IPv4 to owned IPv4. Will give it another month or so and see where it ends up.
Disappointed in San Jose consistently at the bottom.
Overview of data and servers:
Covering first ~2 months of ~340 guard relays across 4 different providers in 5 different US-based geographic locations.
All relays with roughly the same average life of ~2 months by the April date.
The servers are all 88 threads to 128 threads with 384GB to 768GB RAM and each on 10 Gbps dedicated unmetered connections.
The servers are all running Ubuntu 24.04.02 with latest Tor relay versions.
Half the servers using owned IPv4 with my ASN and half using rented IPv4 with provider ASN.
Each server is roughly $500/mo and majority are privately negotiated because list prices are 2-5x higher.
Every provider said they’re comfortable with Tor traffic but most weren’t familiar with the details.
Source: All data from metrics.torproject.org
Table and chart attached as screenshots and text table pasted below.
Table in text:
Average Bandwidth per Relay
Provider Apr 12th 2025 Apr 3rd 2025 March 30th 2025 March 22nd 2025
1 - New York 8.70 8.25 7.91 7.38
2 - Chicago 8.22 5.44 4.73 4.24
1 - Detroit 5.25 5.17 4.55 4.60
3 - Dallas - Server 1 4.95 2.82 2.46 4.34
3 - Dallas - Sever 2 4.73 2.84 2.76 3.52
4 - San Jose 3.38 3.90 3.26 3.06
For Felix, most relays have HsDir flag and average uptime for a week or two or three, depending on when last Tor version bumped.
Likely when you review relays had just been upgraded so HsDir flag often drops for a few days.
On Saturday, April 5th, 2025 at 1:03 PM, Felix via tor-relays <tor-relays@lists.torproject.org> wrote:
Hi
Part 3 - Looking for feedback on our Tor relay configuration
decision:
Looking for guidance on optimizing server / bandwidth spending for
Tor guard / middle relays across datacenters.
https://metrics.torproject.org/rs.html#search/contact:1aeo
2Gbps means 1Gbps in and 1Gbps out.
Thanks for the informations.
Overall, using 16 Gbps out of 30 Gbps purchased –
roughly half our bandwidth is idle / “wasted”
Is it right that most (all?) relays are not older than mid of March?
If so please take a look at
https://blog.torproject.org/lifecycle-of-a-new-relay/ .
As for as I see the relay status page shows not a single relay with a
HsDir flag and no uptime above 2 days.
Gaining a trustful relay with good traffic needs much more time alive
of the relays (keys). Easily 3 to 6 months.
The relays are on up to date Tor versions 4.8.15 and 4.8.16 what is
good!
My recommendation is to let them brew for 2 months. The situation will
change.
Cheers and happy relaying, Felix
tor-relays mailing list – tor-relays@lists.torproject.org
To unsubscribe send an email to tor-relays-leave@lists.torproject.org
tor-relays mailing list – tor-relays@lists.torproject.org
To unsubscribe send an email to tor-relays-leave@lists.torproject.org
Attachments: